一:介绍
定义:线性回归在假设特证满足线性关系,根据给定的训练数据训练一个模型,并用此模型进行预测。为了了解这个定义,我们先举个简单的例子;我们假设一个线性方程 Y=2x+1, x变量为商品的大小,y代表为销售量;当月份x =5时,我们就能根据线性模型预测出 y =11销量;对于上面的简单的例子来说,我们可以粗略把 y =2x+1看到回归的模型;对于给予的每个商品大小都能预测出销量;当然这个模型怎么获取到就是我们下面要考虑的线性回归内容;并且在现实中影响销量(y)的因素好有很多,我们就拿商品大小(x₁),商品价格为例 (x₂)为例:
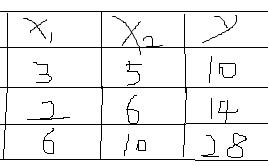
在机器学习之前,获取数据是第一步(无米难巧妇之炊),假定我们的样本如下:其中x1 为商品的大小,x2 为商品的价格,y 为商品的销量;
二 :模型推导
为了推导模型,在假设数据满足线性模型条件下,可以设定线性模型为;x1特征为商品的大小,X2特征为商品的价格;
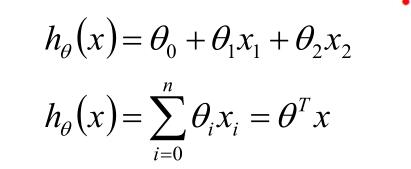
模型假定好后,我们把训练数据代入上面的设定模型中,可以通过模型预测一个样本最终值;

然后样本真实值 y 和模型训练预测的值之间是有误差 ε ,再假设训练样本的数据量很大的时候,根据中心极限定律可以得到 ∑ε 满足 (u ,δ²)高斯分布的;由于方程有截距项 ,故使用可以 u =0; 故满足(0,δ²)的高斯分布;
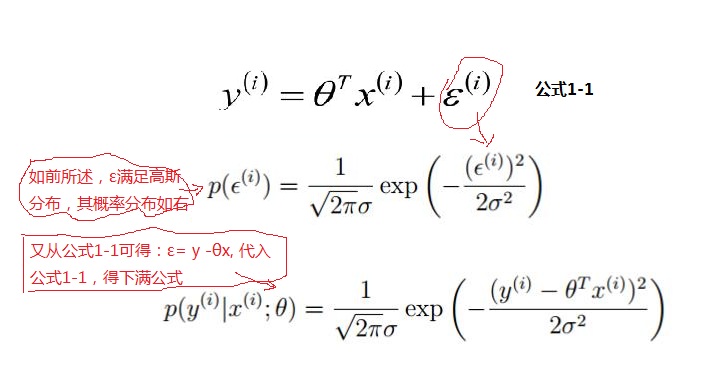
如上面可知,对于每一个样本 x ,代入到 p (y |x ;θ) 都会得到一个y 的概率;又因为设定样本是独立同分布的;对其求最大似然函数:
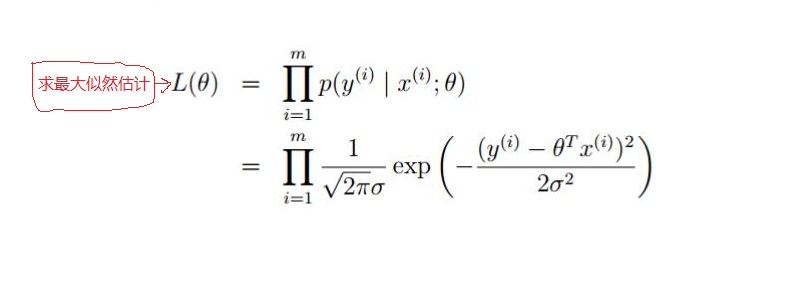
对其化简如下:

以上就得到了回归的损失函数最小二乘法的公式,对于好多介绍一般对线性回归的线性损失函数就直接给出了上面的公式二乘法。下面我们就对上面做了阶段性的总结:线性回归,根据大数定律和中心极限定律假定样本无穷大的时候,其真实值和预测值的误差ε 的加和服从u=0,方差=δ²的高斯分布且独立同分布,然后把ε =y-Øx 代入公式,就可以化简得到线性回归的损失函数;
第二步:对损失函数进行优化也就是求出w,b,使的损失函数最小化;第一种方法使用矩阵(需要满足可逆条件)
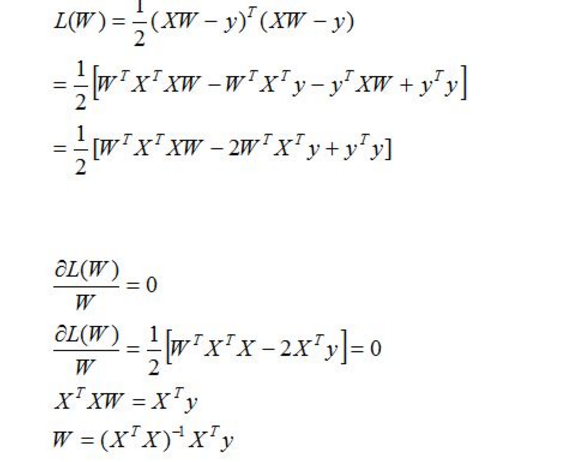
以上就是按矩阵方法优化损失函数,但上面方法有一定的局限性,就是要可逆;下面我们来说一说另外一个优化方法 梯度下降法;对于梯度下降法的说明和讲解资料很多,深入的讲解这里不进行,可以参考:http://www.cnblogs.com/ooon/p/4947688.html这篇博客,博主对梯度下降方法进行了讲解,我们这里就简单的最了流程解说;

总体流程就如上所示,就是求出每个变量的梯度;然后顺着梯度方向按一定的步长a,进行变量更新;下面我们就要求出每个变量的梯度,下面对每个θ进行梯度求解公式如下:

如上我们求出变量的梯度;然后迭代代入下面公式迭代计算就可以了:

上面每次更新变量,都要把所有的样本的加起来,数据量大的时候效率不高,下面还有一种就是按单个样本进行优化,就是随机梯度下降:
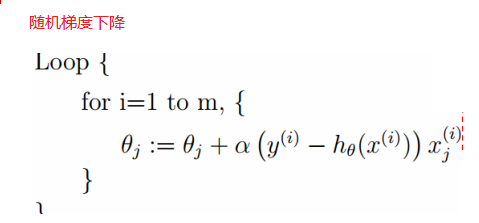
按上面优化步骤就可以求出w,b,就可以获得优化的特征方程:说这么多先上个代码:
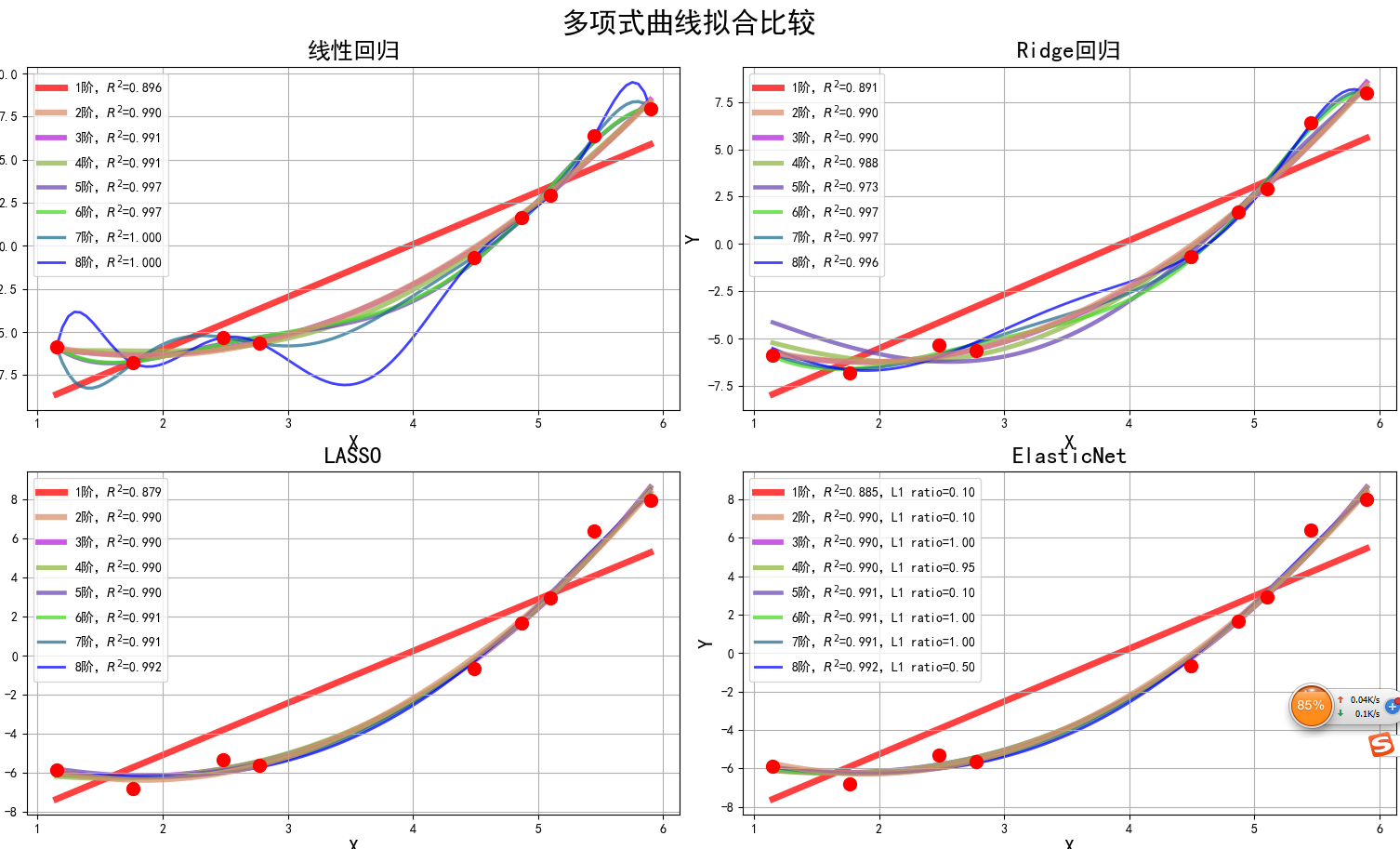
# -*- coding:utf-8 -*-import numpy as npimport warningsfrom sklearn.exceptions import ConvergenceWarningfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.linear_model import LinearRegression, RidgeCV, LassoCV, ElasticNetCVimport matplotlib as mplimport matplotlib.pyplot as pltif __name__ == "__main__": warnings.filterwarnings(action='ignore', category=ConvergenceWarning) np.random.seed(0) np.set_printoptions(linewidth=1000) N = 9 x = np.linspace(0, 6, N) + np.random.randn(N) x = np.sort(x) y = x ** 2 - 4 * x - 3 + np.random.randn(N) x.shape = -1, 1 y.shape = -1, 1 p = Pipeline([ ('poly', PolynomialFeatures()), ('linear', LinearRegression(fit_intercept=False))]) mpl.rcParams['font.sans-serif'] = [u'simHei'] mpl.rcParams['axes.unicode_minus'] = False np.set_printoptions(suppress=True) plt.figure(figsize=(8, 6), facecolor='w') d_pool = np.arange(1, N, 1) # 阶 m = d_pool.size clrs = [] # 颜色 for c in np.linspace(16711680, 255, m): clrs.append('#%06x' % c) line_width = np.linspace(5, 2, m) plt.plot(x, y, 'ro', ms=10, zorder=N) for i, d in enumerate(d_pool): p.set_params(poly__degree=d) p.fit(x, y.ravel()) lin = p.get_params('linear')['linear'] output = u'%s:%d阶,系数为:' % (u'线性回归', d) print output, lin.coef_.ravel() x_hat = np.linspace(x.min(), x.max(), num=100) x_hat.shape = -1, 1 y_hat = p.predict(x_hat) s = p.score(x, y) z = N - 1 if (d == 2) else 0 label = u'%d阶,$R^2$=%.3f' % (d, s) plt.plot(x_hat, y_hat, color=clrs[i], lw=line_width[i], alpha=0.75, label=label, zorder=z) plt.legend(loc='upper left') plt.grid(True) # plt.title('线性回归', fontsize=18) plt.xlabel('X', fontsize=16) plt.ylabel('Y', fontsize=16) plt.show() 运行代码后可见打印控制台信息如下:
/home/mymotif/PycharmProjects/py2/venv/bin/python /opt/pycharm-2018.1.3/helpers/pydev/pydev_run_in_console.py 40267 39581 /home/mymotif/PycharmProjects/py2/ml1.pyRunning /home/mymotif/PycharmProjects/py2/ml1.pyimport sys; print('Python %s on %s' % (sys.version, sys.platform))sys.path.extend(['/home/mymotif/PycharmProjects/py2'])线性回归:1阶,系数为: [-12.12113792 3.05477422]线性回归:2阶,系数为: [-3.23812184 -3.36390661 0.90493645]线性回归:3阶,系数为: [-3.90207326 -2.61163034 0.66422328 0.02290431]线性回归:4阶,系数为: [-8.20599769 4.20778207 -2.85304163 0.73902338 -0.05008557]线性回归:5阶,系数为: [ 21.59733285 -54.12232017 38.43116219 -12.68651476 1.98134176 -0.11572371]线性回归:6阶,系数为: [ 14.73304784 -37.87317493 23.67462341 -6.07037979 0.42536833 0.06803132 -0.00859246]线性回归:7阶,系数为: [ 314.3034477 -827.89447307 857.33293579 -465.46543848 144.21883914 -25.67294689 2.44658613 -0.09675941]线性回归:8阶,系数为: [-1189.50155038 3643.69126592 -4647.92962086 3217.22828675 -1325.87389914 334.32870442 -50.57119322 4.21251834 -0.14852101]PyDev console: starting.Python 2.7.12 (default, Dec 4 2017, 14:50:18) [GCC 5.4.0 20160609] on linux2
图像显示如下:
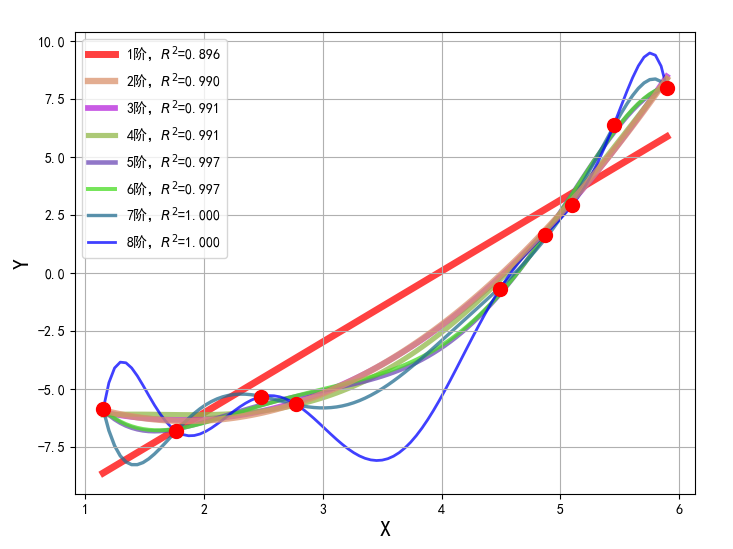
从上面图像可以看出,当模型复杂度提高的时候,对训练集的数据拟合很好,但会出现过度拟合现象,为了防止这种过拟合现象的出现,我们在损失函数中加入了惩罚项,根据惩罚项不同分为以下:
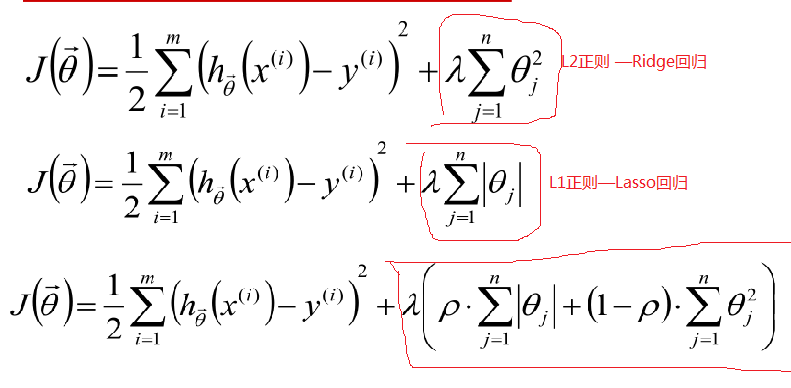
最后一个为Elastic Net 回归,把 L1 正则和 L2 正则按一定的比例结合起来:
L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。在所有特征中只有少数特征起重要作用的情况下,选择Lasso比较合适,因为它能自动选择特征。而如果所有特征中,大部分特征都能起作用,而且起的作用很平均,那么使用Ridge也许更合适。对于各种回归的比较可以看下图: